Federal officials tap open-source standard to improve GenAI access to public data

As more and more Americans turn to generative AI tools to answer their questions, federal officials are working to ensure that third-party chatbots can more easily rely on public data to inform outputs.
While large language models are good at certain tasks, like understanding and generating content, their responses also raise questions about “data provenance” or where information is originating, Luke Keller, the U.S. Census Bureau’s chief innovation officer and bureau AI lead said at a virtual event last week.
LLMs, which underpin popular chatbots such as ChatGPT, are pretrained on data scraped from the internet and use likelihoods to produce their responses. Government officials have found those models struggle to access federal sources of data, which — despite being already publicly available — might be harder for them to parse.
“What’s interesting, I think, about LLMs in this context, is that they actually amplify an age-old problem that we’ve had, which is: a lot of our data reaches the public through indirect sources,” Keller said.
That’s where a new open-source standard being explored by government officials enters the chat, so to speak. The Census Bureau is among several agencies exploring Model Context Protocol, a standard aimed at bridging the gap between models and data sources so they can provide answers directly based on that information.
“I think we have to accept that … these models are going to be a big part of our lives moving forward,” Keller said. That begs the question of what it looks like to make data “fit-for-purpose” to be used with them, he said.
AI-ready government data
Keller’s comments were made during a virtual panel hosted by the National Institute of Statistical Sciences and the Federal Committee on Statistical Methodology.
That panel of Department of Commerce speakers provided new details about growing federal government efforts to ensure that publicly available data actually works with generative AI tools.
Commerce was an early leader among federal agencies contemplating what it might mean for its vast amounts of public data to be AI-ready, and published best practices roughly a year ago. The same federal statistics committee that co-hosted the panel, FSCM, later built on that work and issued a broad callout for agencies to experiment. That report, among other things, specifically encouraged exploration of MCP.
Now a widely adopted framework, MCP was originally created by Anthropic in 2024 and was donated to an offshoot of the nonprofit Linux Foundation in December. The newly established Agentic AI Foundation — which is aimed at promoting transparency and collaboration in the evolution of AI agents — is currently the steward of the open-source standard.
In addition to Anthropic’s Claude, MCP has been adopted by major platforms, including ChatGPT, Gemini, Copilot.
Keller said widespread adoption within the industry is part of why the Census Bureau began exploring the standard. It has “a lot of wind in its sails,” he said. But while he noted that data owners “should be taking MCP quite seriously,” he also cautioned that the standard isn’t a panacea.
“It’s not the answer. It’s one of many answers,” Keller said.
Nonetheless, the technology can provide benefits for certain uses. Keller described MCP as something of a “switchboard operator” that ensures the LLM is able to access what it needs to respond to a user’s prompt. Data owners, like the Census Bureau, create an MCP server that acts as the intermediary between the model and an existing application programming interface (API) for a dataset.
The Census Bureau’s server is now publicly available on GitHub, with instructions on how users can configure it with their models. While it’s not comprehensive for all Census Bureau data yet, the agency is working on that. Keller said the plan is to experiment, start small, iterate, and follow in areas where there is demand.
Experiments and launches
Officials elsewhere in the government are similarly making moves to deploy and explore the technology.
Just last month, the Government Publishing Office announced its own MCP server for data available on GovInfo, which hosts a trove of congressional documents, Federal Register postings, and federal statutes. That server was similarly made publicly available on GitHub and invites feedback.
“For the first time, GPO is providing an officially supported method to allow the use of LLMs and AI agents to ‘converse’ with GovInfo, the world’s only certified trustworthy digital repository,” the legislative branch agency said in its January announcement. “This could benefit legal researchers, policy analysts, data consumers, government users, academics, compliance assistants, and many other users.”
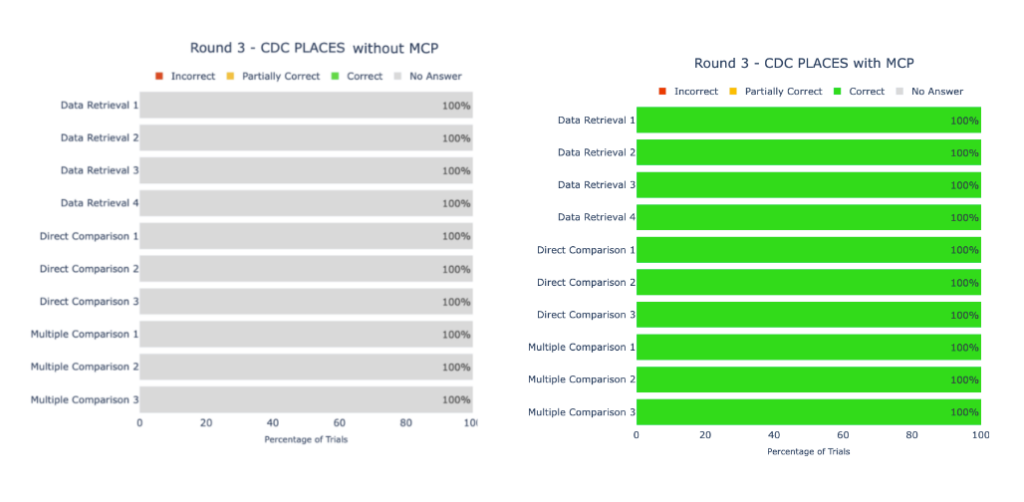
A recent pilot study conducted by several fellows with U.S. Digital Corps., meanwhile, probed use of MCP servers for data produced by the Centers for Disease Control and Prevention and USASpending, reporting particularly promising results.
Initial test queries to ChatGPT and Gemini found 0% accuracy for USASpending-related information and just 2.1% accuracy for questions related to CDC PLACES data, per a report from the fellows. With the implementation of MCPs, the accuracy rose to 95% across both of the datasets.
“Our results indicate the enormous potential of MCPs to advance accessibility of federal data,” a report from those fellows found. “With MCP deployment, agencies can enable accurate, reliable machine interpretation and unlock more nuanced interactions with federal data for academic research, policy development, and program evaluation.”
‘Night-and-day’
Bella Mendoza, a data scientist in Commerce’s Office of the Undersecretary for Economic Affairs and one of the fellows who conducted that pilot, discussed those findings during the virtual event last week and demonstrated the difference a server can make.
Using Claude Sonnet 4 as an example, Mendoza asked the chatbot for CDC PLACES data about the percentage of adults with short sleep durations in Worcester County, Mass., in 2018.
The model first searched the web and then attempted to reach the dataset directly, but it quickly moved on to other options when that failed. Ultimately, Claude concluded that it couldn’t find the stat Mendoza was looking for and provided steps on how to access the data.
Mendoza then repeated the same query with the MCP server implemented within Claude, and the chatbot immediately produced a response, including a confidence interval and the population of the county.
“Hopefully, that kind of shows you a night-and-day difference with what the technology provides,” Mendoza said. Though it was just one response, they continued, the example “was really indicative of its performance over a suite of different questions.”
In addition to the publication of the report on the General Services Administration’s Technology Transformation Services’ GitHub, the agency is also hosting a public collection of MCPs of open government datasets. Currently, the Census Bureau is the only MCP on that list.
Annual AI use cases inventories, however, suggest that other agencies are also exploring the technology for uses internally. The Centers for Medicare and Medicaid Services, as well as the Treasury Department, both reference efforts to deploy MCP servers in their AI use case inventories for 2025.
Measuring accuracy
As Keller noted, MCP isn’t the only solution and other AI-ready data efforts are simultaneously underway.
Dominique Duval-Diop, deputy chief data officer and acting chief data officer at Commerce, said during the panel that in the year since the department released its AI-ready guidelines, “there’s been a huge amount of uptake.”
The focus for Commerce now is how those practices become part of operations, she said.
Duval-Diop, a former U.S. chief data scientist, highlighted an ongoing collaboration with the National Science Foundation and National Secure Data Service to develop an empirical evaluation to measure the accuracy of LLM responses to questions about federal data. That project began last year and officials are looking at developing an open-source prototype tool, Duval-Diop said.
Work to make federal data accessible with new technologies isn’t just a boon for chatbots; it’s consistent with statute.
Travis Hoppe, a member of the FCSM who moderated the event, referenced the government’s obligation under federal law to ensure that data is machine-readable — meaning that information can be easily processed by a computer without loss of semantic meaning. But that law was written in the era of APIs, and in the era of AI its meaning is evolving.
As efforts move forward, Hoppe said agencies “should be looking for the widest, most accessible and appropriate dissemination of our statistical products” — and perhaps even more broadly, all data products.
“I do think that this statistical policy directive applies to all of us in the federal government, all of us who are giving data for the public interest,” Hoppe said. Right now, the technology is “not getting it in the widest, most accessible way.”






